
What do we mean when we talk about ‘the Architecture’ for the London Health Data Strategy?
Gary McAllister, Chief Technology Officer at our colleagues OneLondon attempts to simplify some of the terms used for this important work.
Introduction
The London Health Data Strategy aims to improve the health and well-being of Londoners through the use of data at scale. This statement alone poses several questions such as what is ‘scale’, what data will be used, and how will it be brought together, stored, and secured? Through this blog, I aim to address these questions so that anyone with an interest in the London Health Data Strategy understands ‘The Architecture’ and how it is leveraged to improve outcomes for the citizens of London.
Healthcare data is complex, it is often disorganised and fragmented. This is because healthcare IT solutions have evolved over time and the data was not at the centre of the original system design philosophy. Data is stored within IT systems in a set of containers and each container has a label. For example, a demographics container will store the patient’s details such as their name(s), date of birth and other ancillary information. The complexity comes when more generic data items such as diagnostic tests and narrative information make their way into more generic containers such as ‘diagnosis’, ‘notes’ or ‘results’. This generalisation of the classification of data causes challenges when making sense of the information when extracted for analysis.
Taking the container analogy further, within the container there will be data items, such as a diagnosis. To identify the diagnosis, you would give it a specific code so that it is easy to pinpoint, rather than having to identify the item by its full name. This is the same in healthcare where item codes are given to diagnoses, procedures, medications, and other data items. There are varying nationally recommended codesets to support consistency in identification such as SNOMED-CT[1], ICD10[2], OPCS[3] and DM+D[4]. It would be wonderful if all IT systems used these codesets consistently, but unfortunately, they do not, and many IT systems allow the use of large catalogues of codes that are managed locally. At times information is not coded at all and is stored in free text. This problem is further exacerbated by the multitude of IT systems that exist within each organisation, further compounding the inconsistency of information and the ability to get a clear picture for analytical purposes.
Therefore, it is important that data is well managed and maintained and that the underlying systems are designed to store ‘the same thing, in the same way, all the time’. Without this fundamental, data will always be required to be pre-processed before entering any storage environment. For London, this structure comes in the form of an Observational Medical Outcomes Partnership[5] (OMOP) – Common Data Model (CDM) which enables consistency in the storage and persistence of health information. As data makes its way into the London platform it will carefully be reviewed, categorised, and stored in the appropriate container for downstream use.
With the basics out the way, we can now focus on the data environments being provisioned to support the London Health Data Strategy. These data environments provide containerised storage for London’s health data and are provisioned carefully into two separate platforms for privacy and security. Strict governance is applied above all environments so that access to data is only provided to authorised individuals and that the appropriate rigour is established for the use of the data. A summary of the purpose of these environments is provided below:
- Patient-identifiable (PID) environment, provided by North East London (NEL) – provides a secure, structured set of technologies to host and store identifiable information. The first phase of the programme will look to store data from Primary Care (General Practice), Secondary Care, Mental Health, and Community data from the Commissioning Data Set via the Secondary Use Service[6]. This identifiable environment is highly secure and divided into data repositories for each of London’s five Integrated Care Systems as well as a single environment for the whole of London.
NEL will also provide the tools to support pseudonymisation, a process whereby PID data is anonymised but with a special token that enables the patient to be reidentified in the future. Pseudonymisation is important for specific research programmes where patients may benefit from enhanced treatments or therapies that are developed during the research project. A Pseudonymisation capability will be developed for London that provides a single token service for all projects that require pseudonymisation services.
As well as the above, NEL will deliver a terminology service for London. A terminology service provides the tools to ensure that information means ‘the same thing, in the same way, all the time’. This is an important component for London as it will mean all diagnoses, procedures, medication, and other important facets of the patient record are consistently identifiable. For this to happen, as the data goes through processing into the London platform, the terminology server is referenced to enforce data item consistency. The management of terminologies will be provided by a group of subject matter experts on behalf of London.
- Anonymised environment, provided by Northwest London (NWL) – delivers the Sub-National Secure Data Environment (SN-SDE). This environment stores data in anonymised form for the purposes of research and conforms to the five safes as defined by Health Data Research (HDR)-UK[7]. The five safes ensure that the people who access the data are appropriately vetted, that projects using the data are ethical, technology environments are secure, data is anonymised for the research project, and finally outputs from the environment are controlled for the purposes of research. The NWL environment will conform to all these needs and provide the tooling for access and management of research projects.
Technically, the above is provided by leveraging modernised cloud environments. The strategy for London is to leverage cloud-native technologies which deliver a sustainable, low-cost of maintenance outcome. Leveraging the cloud provides the opportunity to add data at scale without managing the cost of on-site hosting, whilst also providing best-in-class tooling for data isolation, hosting, curation, and analytics. The benefit of the cloud is that as the industry evolves the cloud will evolve too, ensuring that the data platform maintains cadence with best-in-class capabilities.
Secure movement of data between North-East London and North-West London is managed using best practice, secure data movement, encryption technologies and techniques. All data is managed through best practice governance at both a regional and Integrated Care System level. As the data moves between Northeast and Northwest London the data is anonymised and then staged within Northwest London for research use. Northwest London then applies strict processes for access to the data and a robust application process to remove any data or findings from the research environment.
The diagram below provides a high-level, estimated overview of the technologies and capabilities delivered to support the London Data Strategy:
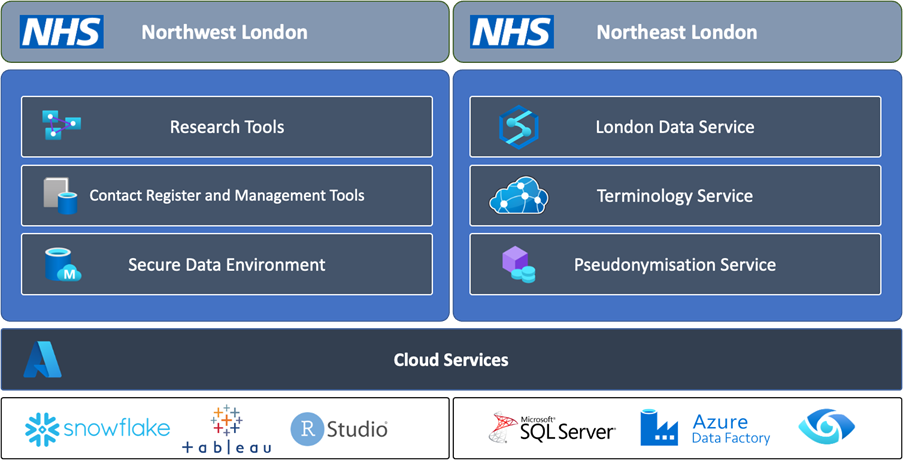
Leveraging the full extent of current cloud-based capabilities the London Data Architecture enables future possibilities for algorithm development, and data at-scale projects for health improvement, and delivers the underpinning capabilities needed to consume additional data sources. Although the architecture above is in the early stages of development, the vision is clear and there is clarity across London that this is the right strategic direction.
Once implemented this architecture will provide the foundations of an ecosystem for a world-leading data-driven health economy.
[1] https://digital.nhs.uk/services/terminology-and-classifications/snomed-ct
[2] https://isd.digital.nhs.uk/trud/users/guest/filters/0/categories/28
[3] https://digital.nhs.uk/data-and-information/information-standards/information-standards-and-data-collections-including-extractions/publications-and-notifications/standards-and-collections/dapb0084-opcs-classification-of-interventions-and-procedures
[4] https://www.nhsbsa.nhs.uk/pharmacies-gp-practices-and-appliance-contractors/dictionary-medicines-and-devices-dmd
[5] https://www.ohdsi.org/data-standardization/
[6] https://digital.nhs.uk/services/secondary-uses-service-sus
[7] https://www.hdruk.ac.uk/access-to-health-data/trusted-research-environments/
